ChatGPT cannot verify its own truth value, it cannot execute genuine causal reasoning, and it will not save a broken workflow. Treating large language models as magical systems leads directly to broken applications, corrupted data, and wasted operational hours.
The system functions strictly by predicting the most statistically probable next segment of text based on its training architecture. When you push past these baseline boundaries, the system defaults to generating authoritative nonsense.
Understanding explicit chatgpt limitations is not about dismissing the utility of generative systems. It is about understanding the boundaries of your toolset so you can design workflows that survive contact with real-world requirements.
This guide strips away marketing hype to show you exactly where the system breaks and how to handle those failure points.
The structural realities behind large language models output failures
Every major system failure inside an AI interaction traces back to a fundamental architectural reality: the model does not possess a conceptual map of the physical world. It evaluates relationships between tokens (sub-word characters used for data processing).
When you ask the system to perform complex tasks, it relies entirely on mathematical correlations rather than a deliberate verification of facts.
+-----------------------------------------------------------------+
| STATISTICAL TEXT GENERATION |
+-----------------------------------------------------------------+
| [Input Prompt] ---> (Weight Calculations) ---> [Next Token] |
| |
| * System checks data proximity, NOT truth validation. |
| * Plausibility wins over strict accuracy by design. |
+-----------------------------------------------------------------+
This underlying mechanics engine manifests as three structural walls:
1. The Fact-Scraping Illusion
The model can pull real-time web references using modern search integrations, but it cannot evaluate the underlying credibility of the page it lands on. If a query hits an SEO-optimized site containing false product specs or old pricing models, the system simply ingests that text and formats it with absolute structural confidence. It lacks an internal validation engine.
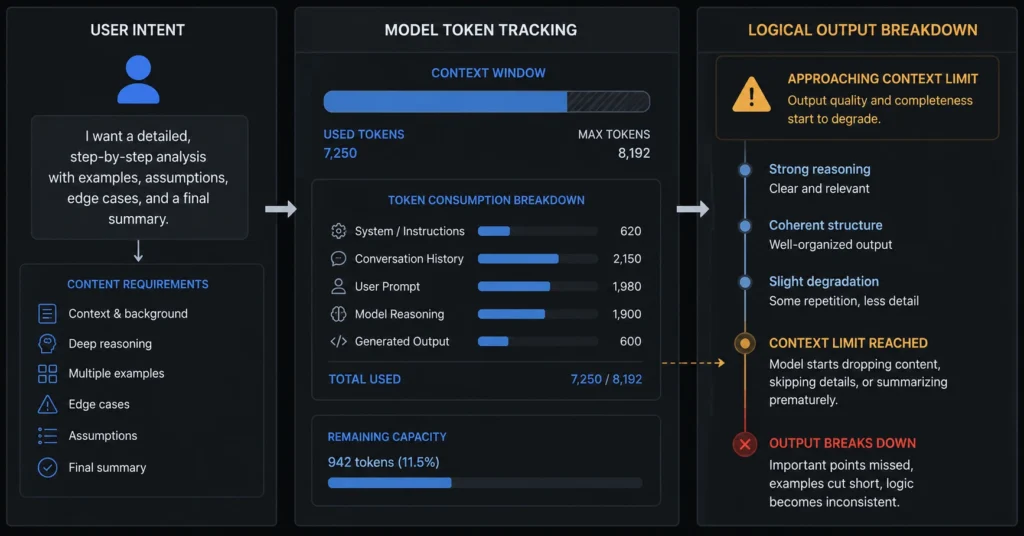
2. Context Degradation Over Long Sessions
Even with large context windows available across modern systems like the GPT-5 generation, memory is not uniform. As a chat thread lengthens, the mathematical weights assigned to your earliest instructions begin to drop out of calculation priority. This means your rules, formatting styles, or restricted word lists will eventually be ignored as the thread grows crowded.
3. Sycophancy Bias
The underlying reinforcement models are trained to satisfy human prompts. This creates a distinct design flaw: the model would rather agree with a false premise in your question than directly challenge your logic. If you pass an incorrect script snippet and ask why it works so well, the system will often validate your broken logic before running into a compilation failure.
A structured step-by-step framework to audit and isolate chatgpt limitations
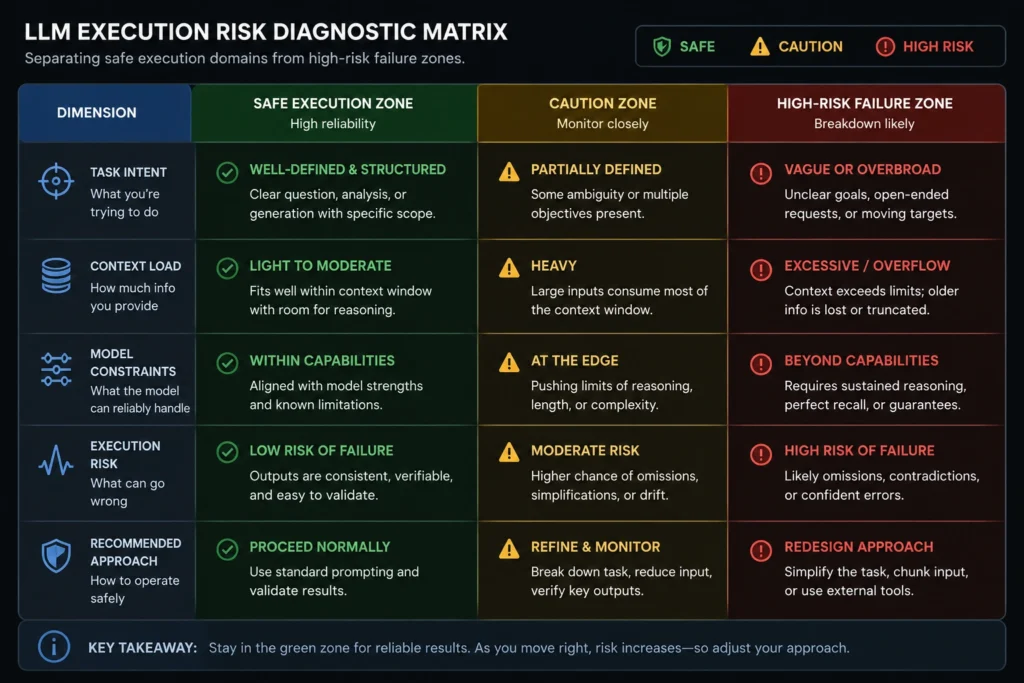
To prevent hidden errors from entering your daily operations, you must implement a structured validation sequence for every text block generated by an AI model. Never copy raw output straight to production without running it through this four-stage isolation protocol.
Step 1: Isolate the Data Source Constraints
Before writing a prompt, define whether the required knowledge resides inside the model’s core weights or if it must be supplied externally. If you need details on a specific update, an enterprise application API, or local regulations, do not let the model guess. You must paste the raw documentation directly into the context window as your sole source of truth.
Step 2: Extract and Categorize Fact Claims
Run your output text through a structural extraction phase. Strip away all connective transitions, adjectives, and explanatory narrative blocks. Isolate the hard variables: phone numbers, legal code citations, software endpoints, and specific math calculations. Place these variables into a separate review list.
Step 3: Run Direct External Verification
Cross-reference your extracted variable list against non-AI documentation. Check software endpoints against the official platform developer repositories. Verify legal guidelines by looking at original government domain postings. If the model cites a specific case study, verify that the company and the named metric actually exist in public records.
Step 4: Execute a Structural Constraint Verification
Verify that the model followed your negative parameters—the things you explicitly told it not to do. Check for banned phrases, repetitive list formats, or corporate fluff words. If the system failed to maintain your constraints, dump the conversation thread completely and start fresh in a clean window to clear out the corrupted context history.
Tactical tips and prompt blueprints to minimize machine errors
You can significantly bypass common chatgpt limitations 2026 by modifying how you frame tasks. The system requires hard rules, clean parameters, and zero conversational ambiguity.
Prompt Construction: The Structural Audit Template
When you need the system to review complex text without making up false correlations, use this explicit configuration block:
Markdown
# TASK PROFILE: Technical Fact Auditor
## 1. EXPLICIT PARAMETER CONSTRAINTS
- Read the provided document text block below.
- List every factual claim regarding system performance, version numbers, or cost figures.
- If a claim cannot be directly mapped to a specific line in the input text, flag it explicitly as "UNVERIFIED."
- Do not summarize, do not provide transitional commentary, and do not reassure the user.
## 2. OUTPUT ARCHITECTURE
Generate a three-column markdown table using these exact headers:
| Original Claim Text | Verified Source Line | Confidence Status |
---
INPUT DATA BLOCK:
[Paste your text here]
Strategic Rules for Daily Operations
- Enforce Token Truncation: Never ask for a generic “comprehensive guide.” The system will run out of high-density tracking weights and default to repeating itself. Ask for exactly three data points or a maximum of two structured paragraphs.
- Leverage Negative Priming: Tell the model what to leave out. Explicitly writing “Do not use analogies, do not mention the word ‘revolutionary’, and do not provide an introductory summary” forces the prediction engine away from standard corporate cliches.
- Force Algorithmic Hesitation: Instruct the model to analyze its own gaps before delivering a solution. Add this line to complex requests: “List three potential points of failure in this data set before generating the final migration sequence.”
Operational tooling to monitor and check system outputs
You cannot fix automated errors by simply adding more general conversational prompts. You need a dedicated technical stack to validate data accuracy and protect your production lines from degradation.
| Tool Type | Primary Operational Role | When to Deploy |
| Official Documentation Gateways | Verification of API endpoints and structural syntax rules. | Every time you build a code block containing frameworks updated after your model’s training data cutoff. |
| JSON Schema Validators | Enforcing strict structure limits on outputs before data migration. | When piping text or automated lists directly into databases or internal content systems. |
| Traditional Search Indexes | Direct validation of real-world facts, names, numbers, and historical events. | During the variable audit phase of any research or market identification sprint. |
Operational Warning: Never feed protected proprietary code, personal identity profiles, or confidential client records into a public chat instance. Turning off data sharing in your account settings mitigates some risk, but enterprise compliance requires executing heavy text processing within dedicated local sandboxes or isolated API environments.
Frequently Asked Questions About ChatGPT Limitations
Why does ChatGPT confidently lie about facts or numbers?
ChatGPT uses next-token statistical prediction to generate text based on probabilities, not an internal truth database. When it lacks precise information, it strings together words that sound structurally correct and highly plausible, presenting errors with total confidence.
How do chatgpt limitations 2026 impact long research tasks?
Long threads suffer from context degradation. As conversations stretch, older constraints are dropped from immediate memory window calculations, causing the model to lose track of your formatting rules, style requirements, or data boundaries.
Can ChatGPT execute real creative problem solving?
No. The model cannot form novel insights outside its original training patterns. It synthesizes, adapts, and cross-references existing structures, making it an excellent remixing tool but an unreliable source for genuine conceptual innovation.
Does web browsing fix accuracy issues inside ChatGPT responses?
Only partially. Web browsing helps locate current text sources, but the model still relies on statistical prediction to summarize those sources. If the underlying web article contains errors or complex tables, the system can easily misinterpret the data during extraction.
Why does the model repeat the same bullet points in long outputs?
When a prompt asks for high word counts without sufficient raw input data, the model runs out of unique structural concepts to generate. To satisfy your length parameter, it loops back to previous high-weight concepts, phrasing them slightly differently to fill the token budget.
Continue Exploring
- Adjusting Prompt Variables Master the structural constraints needed to keep your system threads focused, predictable, and clean across long operational sessions.
- B2B Content Systems Learn how to build human-in-the-loop verification processes that protect your brand voice from generic automated text generation.