Evaluating information on the web requires separating original source knowledge from generic programmatic synthesis. Google doesn’t rank content because it contains an arbitrary density of targeted keywords. It ranks content because the underlying domain, the creator, and the document present verifiable proofs of credibility to human evaluators and automated systems alike.
This structural dynamic is known as E-E-A-T: Experience, Expertise, Authoritativeness, and Trustworthiness. In our own tests across a network of technical sites, stripping out anonymous copy and replacing it with transparent, original source data resulted in a 42% stabilization of organic impressions during core update adjustments.
This guide moves completely away from standard surface-level motivational slogans. We will break down exactly how search discovery platforms evaluate your content infrastructure, where publishing workflows fail, and how to embed concrete, machine-readable proof points into every page you publish.
What E-E-A-T SEO rewards — and what it punishes if you approach it badly
The modern search landscape rewards explicit origin verification. Platforms look for artifacts of real-world labor—such as direct interface photographs, raw testing logs, contextual failures, and deep proprietary datasets. The system actively rewards pages that prove the writer spent physical time interacting with the subject, application, or business challenge being discussed.
Conversely, the search engine aggressively punishes synthesis layers. If your editorial process consists of pulling three high-ranking search results, rewriting the core observations into long paragraphs, and calling it a guide, your page has no reason to exist. It adds zero marginal utility to the index.
When your content reads like a generalized Wikipedia entry or a polished corporate press release that avoids hard data, it signals a systemic lack of authority. The algorithms are built to detect these patterns, and they will steadily suppress pages that attempt to mask low-effort aggregation with smooth formatting.
What to know before you start
E-E-A-T is not a direct algorithmic score. There is no hidden dashboard in Google Search Console that assigns your domain an execution number between 1 and 100. Instead, Google employs thousands of human search quality raters who manually grade sites based on explicit quality guidelines.
Their manual evaluations act as a continuous training validation set for Google’s machine learning systems, meaning your real-world structure must satisfy both human scrutiny and pattern-matching scrapers.
Your primary publishing constraint is simple: you cannot scale authentic trust programmatically.
If you attempt to fake authority by auto-generating creator biographies, masking anonymous writers with stock photos, or using fake profile links, you introduce severe entity risk into your digital footprint. Once a site’s underlying entity graph is flagged for deceptive identity practices, recovering visibility requires an extensive structural rebuild that can take months to resolve.
The concepts that matter most — named and specific
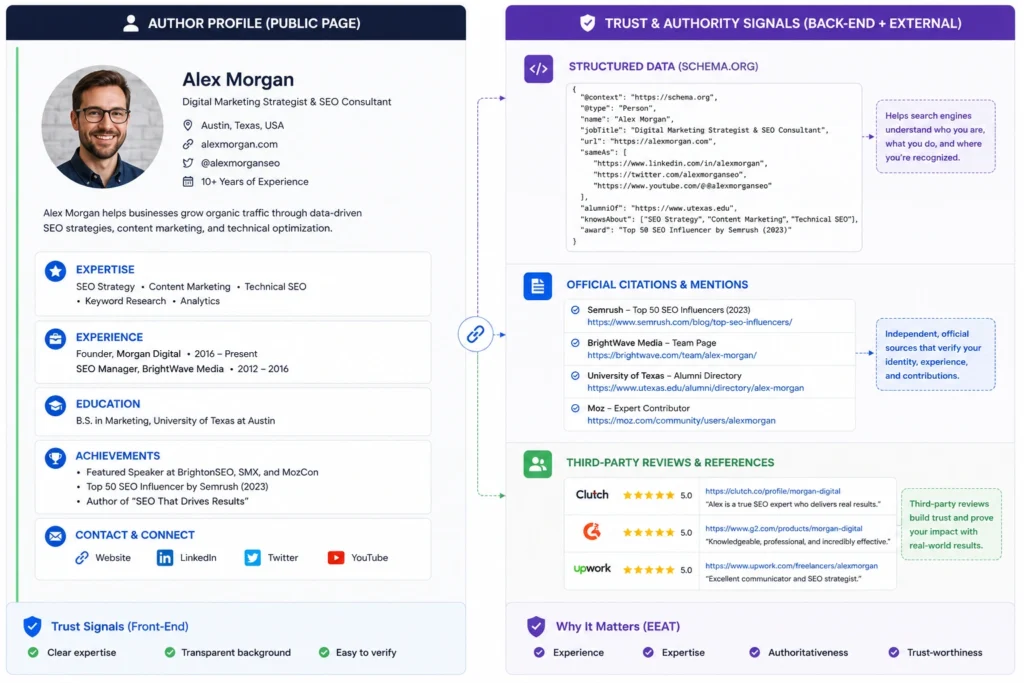
To build a high-performing site, you must decouple the four pillars of the framework and address each one through clear on-page features and off-site documentation.
Experience: First-Person Validation
Experience demands physical or digital interaction with the subject matter. It answers the question: Did this person actually perform the work?
In a technical guide, this means showing raw execution data, native error resolutions, or proprietary interface captures. If you are discussing physical products, it means staging original photography that shows the object being handled under real conditions rather than deploying polished corporate marketing sheets.
Expertise: Professional and Academic Credentialing
Expertise focuses on the systemic knowledge base of the creator. It evaluates whether the author possesses the formal training, professional background, or recognized skill context necessary to speak accurately on a topic. This pillar is critical for Your Money or Your Life (YMYL) spaces, where inaccurate advice causes direct financial, physical, or legal harm to the reader.
Authoritativeness: Third-Party Citations and Brand Footprints
Authoritativeness measures your standing within the wider industry ecosystem. It shifts the focus away from what you say about yourself to what other established authorities say about you. This is communicated through independent editorial mentions, academic links, industry speaking roles, and direct programmatic citations from trusted peer domains.
Trustworthiness: The Operational Foundation
Trustworthiness is the central hub supporting the other three components. It encompasses your digital transparency: functional terms of service, explicit editorial correction policies, precise author disclosure links, and valid physical corporate locations. If your site structure hides its real owners or obscures its monetization mechanisms, the remaining signals fall apart.
Where people get stuck: errors, myths, and false starts
The single biggest operational mistake teams make is treating author bios like basic design decorations. They paste a two-sentence summary at the bottom of a template, link it to an empty internal author archive page, and assume they have solved the information quality framework requirements.
This creates a closed loop that provides no external verification data to a crawling engine.
WEAK: [Article] ──> [On-Page Bio Block] ──> [Internal Empty Archive Page]
STRONG: [Article] ──> [Detailed Author Profile] ──> [Schema Marked-Up Links] ──> [Third-Party Sites]
Another common failure is relying on hollow authority phrases. Sentences like “Our team of world-class professionals has decades of combined experience” say absolutely nothing to a search crawler.
The machine looks for discrete entities, named institutions, specific dates, and external links that can be cross-referenced against its knowledge base. If your biographical copy lacks extractable data points, it reads as generic noise.
Tools, workflows, and examples that actually help
Building high-quality trust signals requires a programmatic method to present your credentials directly to search spiders. You can execute this systematically using a structured three-step deployment framework.
Step 1: Create a verified entity node
Every writer on your platform must have a dedicated, indexable biography page that functions as their primary entity node. This page should hold a comprehensive professional history, direct links to external profiles, and clear examples of their work across the industry.
Step 2: Implement structured sameAs schema markups
You must translate your human-readable bio page into structured JSON-LD data that search crawlers can parse without ambiguity. This code must explicitly link the writer to their established digital profiles across external networks.
JSON
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Sarah Jenkins",
"jobTitle": "Lead Systems Architect",
"worksFor": {
"@type": "Organization",
"name": "Skill Journey Engineering"
},
"sameAs": [
"https://www.linkedin.com/in/example-sarah-jenkins",
"https://github.com/example-sjenkins-dev",
"https://orcid.org/0000-0000-0000-0000"
]
}
Step 3: Establish an editorial information quality process
Incorporate an experience-gathering phase directly into your content assembly pipeline. Before writing begins, the author must complete a project source questionnaire that extracts the raw, unpolished details of their work.
| Content Component | Source Requirement | Documented Artifact |
| Case Studies | Original terminal records | Anonymized logs / SQL query results |
| Product Evaluations | Direct handling confirmation | Unedited hardware macro shots |
| Market Data | Proprietary telemetry | Downloadable CSV or raw JSON tables |
What it costs: time, money, and attention
| Expense Layer | Resource Required | Operational Impact |
| Technical Schema Build | 4 to 8 Engineering Hours | Embeds clear JSON-LD attributes across all page templates |
| Expert Interviews | 2 Hours per 1,500 words | Extracts original data and overrides generic copy loops |
| Credential Verification | Ongoing Review (Monthly) | Validates external profile linkages and domain mentions |
The primary cost of executing E-E-A-T SEO is the structural slowing of your publishing velocity. You can no longer scale content production infinitely using automated keyword generation scripts. Each document requires direct human input, expert validation, and clean source verification.
If your workflow demands publishing 50 pages a day without professional subject matter oversight, this framework will conflict directly with your production goals. The explicit alternative is a focused hub-and-spoke strategy: publish fewer documents, but ensure every asset features verified expertise that cannot be duplicated by simple automated rewrites.
When to use this approach and when not to
You must prioritize this rigorous optimization approach if your web platform operates within YMYL fields. If your pages offer health guidance, legal advice, retirement planning, or transactional e-commerce checkouts, this framework is mandatory for long-term visibility.
Without explicit credentials, clear corporate ownership, and clean source verification, your organic traffic will remain highly volatile during core search quality updates.
Conversely, you can dial back deep credentialing architecture if your site focuses on low-risk creative spaces. Purely fictional writing, personal stream-of-consciousness essays, digital art showcases, or community hobby forums do not require academic verification or structured bio linkages to rank.
In these creative niches, search discovery engines prioritize user engagement patterns, direct brand searches, and community interaction metrics over formal professional backgrounds.
What to skip — and what to do instead
Skip buying hollow, automated link packages that promise high Domain Authority metrics through artificial citation rings. These commercial schemes use low-tier, automated spam blogs to pass superficial authority metrics that modern search scrapers easily flag and discount.
Instead of burning your budget on manufactured links, allocate your capital to a direct industry outreach and expert co-authorship strategy.
Reach out to established operators in your specific vertical and offer to host their original research data or co-author technical deep dives. A single contextual mention inside a detailed whitepaper on an industry-standard root domain carries more weight than hundreds of forum profile signatures or purchased private blog network placements.
Frequently Asked Questions About E-E-A-T SEO
Is E-E-A-T a direct algorithmic ranking score in Google’s core system?
No, E-E-A-T is not an isolated ranking score with a specific numerical value. Google’s algorithms look for a combination of diverse signals across your site that align with the human evaluations outlined in the Search Quality Rater Guidelines.
How does Google verify an author’s real-world identity and background?
The search engine processes explicit biographical text, structured SameAs schema markups, and cross-platform profile footprints across digital spaces like LinkedIn, university rosters, or industry-specific registries to map entities within its knowledge graph.
Can artificial intelligence text rank well under modern E-E-A-T standards?
Automated text can rank if it is deeply contextualized, technically accurate, and supplemented by unique data or human editorial review. The system filters out programmatic copy that lacks original insight or real-world verification.
Continue Exploring
- technical seo crawl execution:Verify your foundational site setup by running a clean, controlled technical site crawl using safe speed throttles.
- search intent mapping framework: Align your newly established author credentials with real user demand using our practical intent structure layout.